

В два часа ночи по Москве на сервере просыпается первый агент. К семи утра пять агентов успевают: проанализировать вчерашнюю выручку, предложить три варианта текста для рассылки, проверить позиции статей в поиске, оценить эффективность рекламных креативов и подготовить еженедельный отчёт. Человек приходит утром к готовым предложениям — и принимает решения.
Это не фантазия. Это работающая система для PARTYstation — подписочного сервиса квиз-игр для Smart TV. Тысячи подписчиков, 100+ тысяч рублей выручки в день, пять AI-агентов управляют маркетингом.
Вот как это устроено.
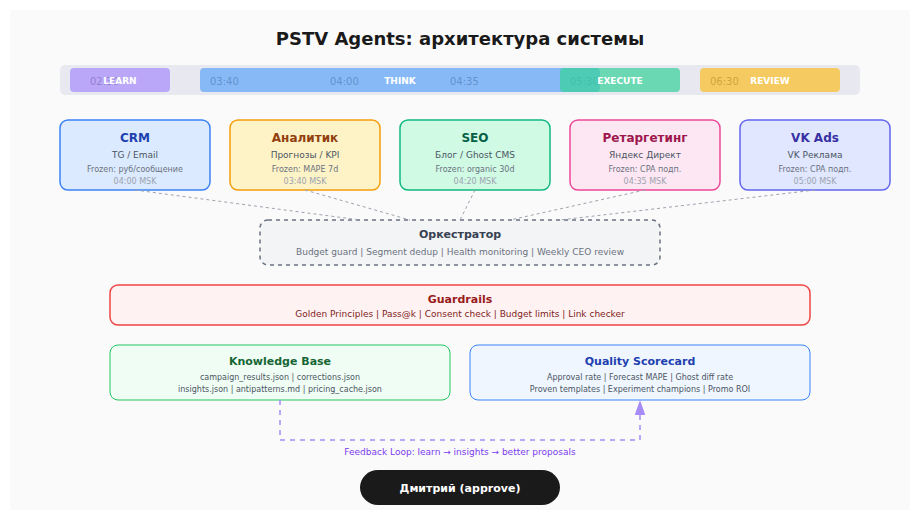
Пять агентов, пять каналов
Каждый агент — это папка с тремя файлами: config.yaml (расписание, правила, метрики), prompt.md (роль и инструкции), tools.py (что агент умеет делать). Плюс папка knowledge с накопленным опытом.
CRM-маркетолог — рассылки в Telegram и email. Предлагает тексты кампаний, промокоды, триггерные сообщения. Например: после длинной игровой сессии отправить предложение перейти на годовую подписку.
Аналитик — прогнозы выручки, мониторинг аномалий, еженедельные отчёты. Считает MAPE прогноза и сам понимает, когда его модель устарела.
SEO-контент — статьи в блог, лендинги, семантическое ядро. Пишет черновики в Ghost CMS. Если человек правит текст — агент видит diff и спрашивает: "Почему вы поменяли заголовок?"
Ретаргетинг — управление рекламой в Яндекс Директе. Ставки, бюджеты, аудиторные сегменты. Умеет загружать аудитории в Яндекс Аудитории и создавать look-alike.
VK Ads — реклама в VK. Look-alike на базе нескольких тысяч вовлечённых пользователей. Постинг в группу vk.com/party.station.
РАСПИСАНИЕ: ВСЁ ДО СЕМИ УТРА
02:30 — learn cycle. Все пять агентов анализируют результаты вчерашнего дня. Какие кампании сработали, какие нет. Прогноз vs факт. Правки человека в текстах.
03:35 — обновление цен из базы данных. Агенты никогда не хардкодят цены — читают из кэша, который обновляется ежедневно.
03:40 — аналитик думает. Строит прогноз, проверяет аномалии.
04:00 — CRM думает. Анализирует сегменты, предлагает кампании.
04:20 — SEO думает. Проверяет позиции, предлагает статьи.
04:35 — ретаргетинг думает. Анализирует рекламные кампании.
05:00 — VK Ads думает. Оценивает креативы, предлагает изменения.
05:30 — SEO исполняет. Одобренные статьи публикуются в Ghost.
06:00 — CRM исполняет. Одобренные кампании создаются как черновики.
06:30 — всё готово. Человек открывает дашборд и видит предложения.
Frozen metrics: агент не может переопределить "Хорошо"
Каждому агенту назначена одна метрика, которую он не может изменить. Как val_bpb в autoresearch Карпати — агент оптимизирует, но не решает, что такое "лучше".
- CRM — выручка на одно отправленное сообщение (руб/сообщение).
- Ретаргетинг — стоимость привлечённого подписчика (CPA).
- SEO — органический трафик на статью за 30 дней.
- Аналитик — MAPE прогноза на 7 дней.
Метрику определяет человек. Записывает в config.yaml. Агент видит свой score в quality scorecard и знает: становится лучше или хуже.
Guardrails: три слоя защиты
Слой 1: Golden Principles. Двадцать одно правило, проверяемое кодом. Бренд пишется PARTYstation. Ссылки только с UTM. Цены — из кэша, не из головы. Без длинных тире и LLM-клише. Промокоды — только с одобрения человека.
Нарушение — блокировка auto-approve. Не промпт просит "не делай так", а код проверяет и не пропускает.
Слой 2: Pass@k классификация. Все действия разделены на обратимые и необратимые.
Обратимые (можно откатить): черновик статьи, аналитический отчёт, предложение по стратегии. Порог auto-approve: 30%.
Необратимые (нельзя вернуть): отправка сообщения, расход промокода, запуск рекламы. Порог: 80%. Фактически — всегда через человека.
Слой 3: Budget guard. Оркестратор перед каждым агентом проверяет: дневной бюджет сообщений, рекламный бюджет, лимит промокодов. Превышение — блок.
Micro-experimentation: 30 вариантов за один цикл
Классический A/B тест — два варианта, тысяча человек на каждый, неделя ожидания. Один эксперимент в месяц.
Наш подход: если сегмент достаточно большой (400+ человек), агент предлагает experiment — пачку вариантов текста. Executor делит сегмент на микро-группы по 200 человек + 10% holdout.
Двухэтапная воронка:
Stage 1 (48 часов): все варианты получают по микро-группе. Измеряем click rate. Топ-20% — в следующий раунд. Остальные — в архив с пометкой "почему не сработало".
Stage 2 (7 дней): winners получают укрупнённые группы. Измеряем revenue/msg. Лучший — champion.
При базе 20К в Telegram это до 100 вариантов за цикл. Не рандомный поиск — направленная оптимизация. Каждый инсайт записывается в knowledge.
Feedback loop: агент учится на правках человека
Три канала обратной связи:
CRM: когда человек правит текст перед отправкой — система сохраняет diff (было/стало). При learn cycle агент видит: "Вы написали X, человек поменял на Y". Создаёт вопрос: "Почему?" Человек отвечает в UI — ответ сохраняется в antipatterns.
SEO: Ghost diff collector сравнивает черновик агента с опубликованной версией. Если больше 5% текста изменено — фиксирует правки и спрашивает.
Аналитик: forecast accuracy tracker. Каждый день: прогноз vs факт. Если MAPE > 15% три недели подряд — агент сам предлагает пересмотреть модель.
Все инсайты копятся в insights.json. Антипаттерны — в antipatterns.md. При каждом запуске агент читает их как mandatory knowledge.
Context management: не энциклопедия, а оглавление
Ранняя ошибка — засунуть всё в один prompt. CRM промпт вырос до 28 килобайт. Агент начал терять фокус.
Решение из OpenAI Harness Engineering: prompt.md — короткий (3-5 КБ). Роль, формат, ключевые правила. Детали — в knowledge-файлах. Агент загружает только то, что нужно для текущей задачи.
REGISTRY.md — оглавление: какие файлы знаний существуют, кому какие читать. Mandatory reads в config.yaml — runtime проверяет, что агент прочитал обязательные файлы. Если пропустил — warning в логе.
Doc gardening — еженедельно фоновый процесс проверяет актуальность knowledge base. Если код изменился, а документация нет — алерт.
Model routing: Haiku для анализа, Sonnet для текстов
Не все задачи требуют дорогой модели. Learn cycle — суммирование и анализ — отлично работает на Haiku (в 4 раза дешевле). Proposals и исполнение — Sonnet.
В config.yaml каждого агента:
think: claude-sonnet-4-6
learn: claude-haiku-4-5
execute: claude-sonnet-4-6
Runtime автоматически выбирает модель в зависимости от фазы.
Промокоды: учет каждого кода
На старте система получила 1500 промокодов в трёх пулах (скидка 50% на 1/3/6 месяцев). Каждый код — one-time use.
Агент запрашивает код через tool allocate_promo_code. Прежде чем выдать — promo_manager проверяет: пул не исчерпан, дневной лимит (20 кодов) не превышен, 6-месячные коды только с одобрения человека.
Каждая выдача записывается в promo_ledger.json: какой код, кому, через какую кампанию, использован ли. Learn cycle проверяет Payment DB — если код активирован, помечает.
Quality scorecard показывает: сколько выдано, сколько использовано, конверсия.
Оркестратор: координация без LLM
Ежедневная логика — детерминированная, без вызовов модели:
— Budget guard перед каждым агентом
— Segment dedup: один пользователь — одно сообщение в день
— Health monitoring: таймаут 30 минут, алерт в Telegram при падении
— Scorecard refresh: обновление метрик после всех агентов
Раз в неделю — единственный LLM-вызов: CEO review. Анализ scorecard, экспериментов, forecast accuracy. 3-5 рекомендаций — на одобрение человеку — если ок, становится повесткой для совета AI-эдвайзеров.
Безопасность
Email отправляется только подписчикам с marketing_consent. Два слоя: SQL-фильтр в сегменте + детерминированная проверка в send_campaign. Даже если кто-то создаст сегмент без фильтра — код заблокирует отправку.
Ошибки идут через административного бота, не через боевого. Turso auto-reconnect при потере stream. Команда (16 player_id) исключена из всех аудиторий и кампаний.
Цены никогда не хардкодятся. Pricing cache обновляется ежедневно из Payment DB. История изменений тарифов хранится.
Quality scorecard
Центральный файл quality_scorecard.json. Обновляется каждый learn cycle.
На каждого агента: approval rate (сколько предложений принято с первого раза), rework rate, reject rate. Для CRM: proven templates, средний CR, расход промокодов. Для аналитика: MAPE, bias, model staleness signal. Для SEO: статьи опубликованы, diff rate (сколько правил человек).
Dashboard на /overview показывает: карточка на агента, цветовой код (зелёный > 80%, жёлтый 50-80%, красный < 50%).
Что дальше?
Система работает. Пять агентов, ежедневный цикл, накопление знаний. Но это начало.
Следующие шаги: content agent (управление планом создания контента, и, собственно, создание), compliance agent (юридическая проверка текстов), bizdev assistant (КП партнёрам), а также расширение функционала маркетингового агента.
И главное — micro-experimentation должен начать приносить данные. Первые champions появятся через неделю. Каждый цикл — шаг оптимизации. Каждый инсайт — в knowledge. Система, которая учится, пока мы спим. За первую неделю система принесла дополнительных 10% выручки (и это при очень аккуратных тестах).